

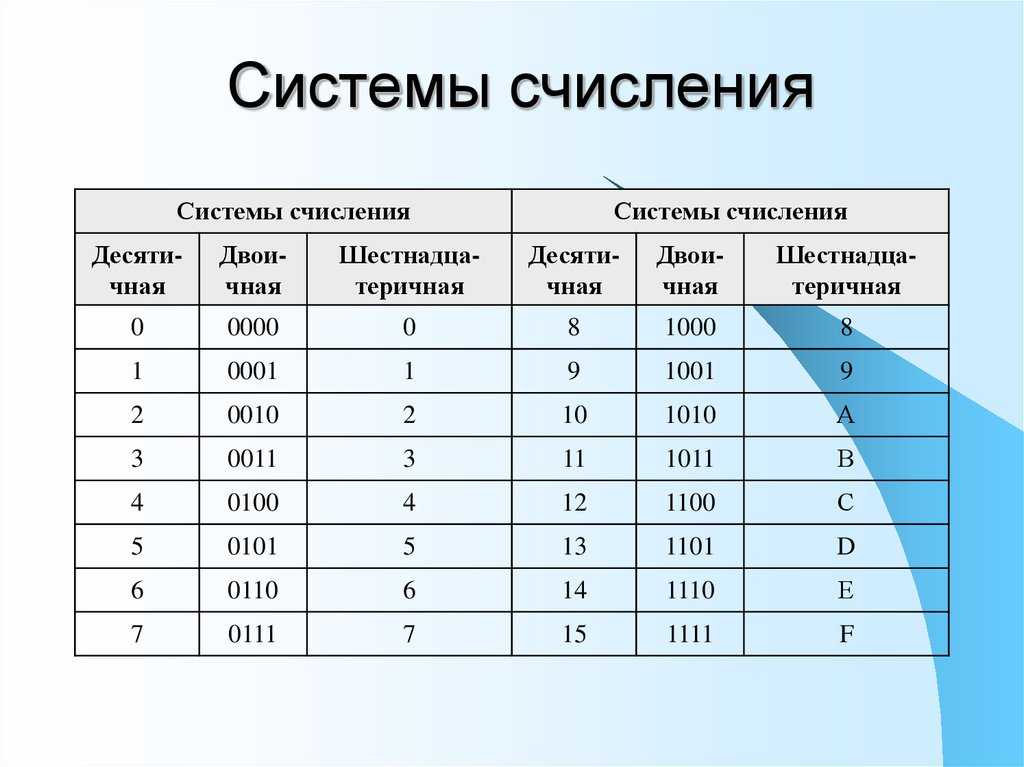
Как ещё оценивают сложность алгоритмов
На протяжении всей статьи мы говорили про Big O Notation. А теперь сюрприз: это только одна из пяти существующих нотаций. Вот они слева направо: Намджун, Чонгук, Чингачгук… простите, не удержался. Сверху вниз: Small o, Big O, Big Theta, Big Omega, Small omega. f — это реальная функция сложности нашего алгоритма, а g — асимптотическая.

Пять нотаций в математическом представлении. Фото: Валерий Жила для Skillbox Media
Несколько слов об этой весёлой компании:
- Big O обозначает верхнюю границу сложности алгоритма. Это идеальный инструмент для поиска worst case.
- Big Omega (которая пишется как подкова) обозначает нижнюю границу сложности, и её правильнее использовать для поиска best case.
- Big Theta (пишется как О с чёрточкой) располагается между О и омегой и показывает точную функцию сложности алгоритма. С её помощью правильнее искать average case.
- Small o и Small omega находятся по краям этой иерархии и используются в основном для сравнения алгоритмов между собой.
«Правильнее» в данном контексте означает — с точки зрения математических пейперов по алгоритмам. А в статьях и рабочей документации, как правило, во всех случаях используют «Большое „О“».
Если хотите подробнее узнать об остальных нотациях, посмотрите интересный видос на эту тему. Также полезно понимать, как сильно отличаются скорости возрастания различных функций. Вот хороший cheat sheet по сложности алгоритмов и наглядная картинка с графиками оттуда:

Сравнение сложности алгоритмов. Скриншот: Валерий Жила для Skillbox Media
Хоть картинка и наглядная, она плохо передаёт всю бездну, лежащую между функциями. Поэтому я склепал таблицу со значениями времени для разных функций и N. За время одной операции взял 1 наносекунду:
Ок, бинарный поиск лучше, но зачем тогда нужен линейный?
Часто студенты спрашивают: «Зачем нужен линейный поиск, если бинарный обходит его по всем позициям?» Отвечаю: линейный поиск работает с любыми массивами, а бинарный — только с отсортированными.
Мы дошли до важного принципа: чем сложнее структура данных, тем более быстрые алгоритмы к ней можно применять. Отсортированный массив — более сложная структура, чем неотсортированный
Забегу вперёд и скажу, что сортировка в общем случае требует от O(n * log(n)) до O(n^2) времени.
Создать дополнительные структуры данных несложно, вот только это не бесплатное удовольствие. Они едят много памяти. Как правило, O(n). Отсюда вытекает довольно логичный, но обидный вывод: время и память — «взаимообмениваемые» ресурсы. Алгоритм можно ускорить, пожертвовав памятью, или решать задачу медленно, зато in-place. Кроме того, почти всегда есть промежуточный вариант.
Что необходимо знать при подсчёте хронометража?
При определении хронометража следует помнить, что самый верный хронометраж текста (например, рекламного) невозможно рассчитать, основываясь только на количество произносимых слов и знаков. При озвучке текста нужно учитывать настроение и саму подачу диктора, поскольку это будет влиять на то, как он сможет прочитать текст, а также это также будет влиять и на его темп чтения.
Следует отметить, что при подсчёте хронометража автоматически учесть особенности каких-то игровых, например, текстов почти невозможно, поскольку они требуют дополнительного места для специальных эффектов, а также логических пауз.
Важную роль при этом играет и язык озвучки. Например, при подсчёте хронометража русского, белорусского, английского языков, он будет приблизительно одинаковым, в отличие от языков, например, восточных стран, где используются совершенно другие словоформы.
Хороший, плохой, средний
У каждого алгоритма есть худший, средний и лучший сценарии работы — в зависимости от того, насколько удачно выбраны входные данные. Часто их называют случаями.
Худший случай (worst case) — это когда входные данные требуют максимальных затрат времени и памяти.
Например, если мы хотим отсортировать массив по возрастанию (Ascending Order, коротко ASC), то для простых алгоритмов сортировки худшим случаем будет массив, отсортированный по убыванию (Descending Order, коротко DESC).
Для алгоритма поиска элемента в неотсортированном массиве worst case — это когда искомый элемент находится в конце массива или если элемента нет вообще.
Лучший случай (best case) — полная противоположность worst case, самые удачные входные данные. Правильно отсортированный массив, с которым алгоритму сортировки вообще ничего делать не нужно. В случае поиска — когда алгоритм находит нужный элемент с первого раза.
Средний случай (average case) — самый хитрый из тройки. Интуитивно понятно, что он сидит между best case и worst case, но далеко не всегда понятно, где именно. Часто он совпадает с worst case и всегда хуже best case, если best case не совпадает с worst case. Да, иногда они совпадают.
42 Какой магазин с наименьшей вероятностью может оказаться мошенническим?
Вы собираетесь купить в интернете новые наушники. Агрегатор товаров, которым вы воспользовались для поиска, предлагает покупку в нескольких магазинах на выбор. Но некоторые из них выглядят очень подозрительно. Какой магазин с наименьшей вероятностью может оказаться мошенническим?
- Магазин, на котором не указаны сведения о продавце (юридический адрес, контакты)
- Магазин, сотрудники которого каждые 5 минут пишут в онлайн-чате поддержки и торопят вас с покупкой выбранных наушников
- Магазин, который в качестве способа доставки предлагает только самовывоз
- Магазин, цена наушников в котором без какой-либо скидки в два раза ниже, чем в других магазинах
Энтропия составных событий. Условная энтрпия
Пусть имеется два независимых опыта Х и У с таблицами вероятностей исходов:
| Исходы испытания | X1 | X2 | … | Xk |
| Вероятности | p(X1) | p(X2) | … | P(Xk) |
| Исходы испытания | Y1 | Y2 | … | Ym |
| Вероятности | p(Y1) | p(Y2) | … | P(Ym) |
Рассмотрим составной эксперимент , состоящий в том, что одновременно выполняются испытания Х и У. Такой эксперимент может иметь km исходов:
X1Y1,X1Y2,…,X1Ym; A2Y1, X2Y2,…,X2Ym;….; XkY1, XkY2,…,XkYm,
где X1Y1 означает, что эксперимент X имел исход X1, а эксперимент Y — исход Y1. Понятно, что неопределенность эксперимента XY будет больше неопределенности каждого из X и Y в отдельности. Энтропия T(XY=E(X) + E(Y).
Если теперь предположить, что результаты опытов X и Y не являются независимыми. В этом случае уже нельзя предполагать, что энтропия составного опыта XY может быть равна сумме энтропий X и Y. Энтропия составного опыта XY будет равна:
E(XY) = — p(X1Y1)log(p(X1Y1)) — p(X1Y2)log(p(X1Y2)) — … — p(X1Ym)log(p(X1Ym)) — …
— p(X2Y1)log(p(X2Y1)) — p(X2Y2)log(p(X2Y2)) — … — p(X2Ym)log(p(X2Ym)) — …
— p(XkY1)log(p(XkY1)) — p(XkY2)log(p(XkY2)) — … — p(XkYm)log(p(XkYm)) ,
Здесь уже нельзя заменить вероятности p(X1Y1), p(X1Y2) и т.д. произведениями вероятностей (p(X1Y1) не равно p(X1)p(Y1), а p(X1)pX1(Y1) — условная вероятность события Y1 при условии X1. Энтропия ЕХ(У) называется условной энтропией опыта Y при условии реализации опыта X.
EX(Y) = p(X1)EX1(Y) + p(Y2)EX2(Y) + … + p(Xk) EXk(Y) или
E(XY) = E(X) + EX(Y)
В любом случае
0 ≤ EX(Y) ≤ E(Y)
Условные значения энтропии для двухбуквенных и трехбуквенных комбинаций в русском языке равны:
E=log(32)=5; E1=4,35; E2= 3,52; E3= 3,01
При языковых исследованиях следует учитывать то, что появление в тексте определенной буквы меняет распределение вероятностей для следующей. Так появление буквы «е» делает весьма вероятным появление еще одной буквы «e». Но появление комбинации «ee» делает появление еще одного «e» крайне мало вероятным. Примеров таких корреляций можно привести достаточно много.








Для языков, использующих латинский алфавит, частоты использования отдельных букв весьма различны. Так если разместить символы букв по мере убывания их частоты использования, то для английского языка мы получим _ETAONRI…, для немецкого — _ENISTRAD… и для французского — _ESANITUR… .Во всех случаях символ _ обозначает пробел между словами.
Классическое определение информационной энтропии (H) выглядит как:
где pi — вероятность того, что реализуется конкретное значение хi (i может принимать значения от 1 до n. I(x) — целочисленная случайная функция (информационное содержимое Х).
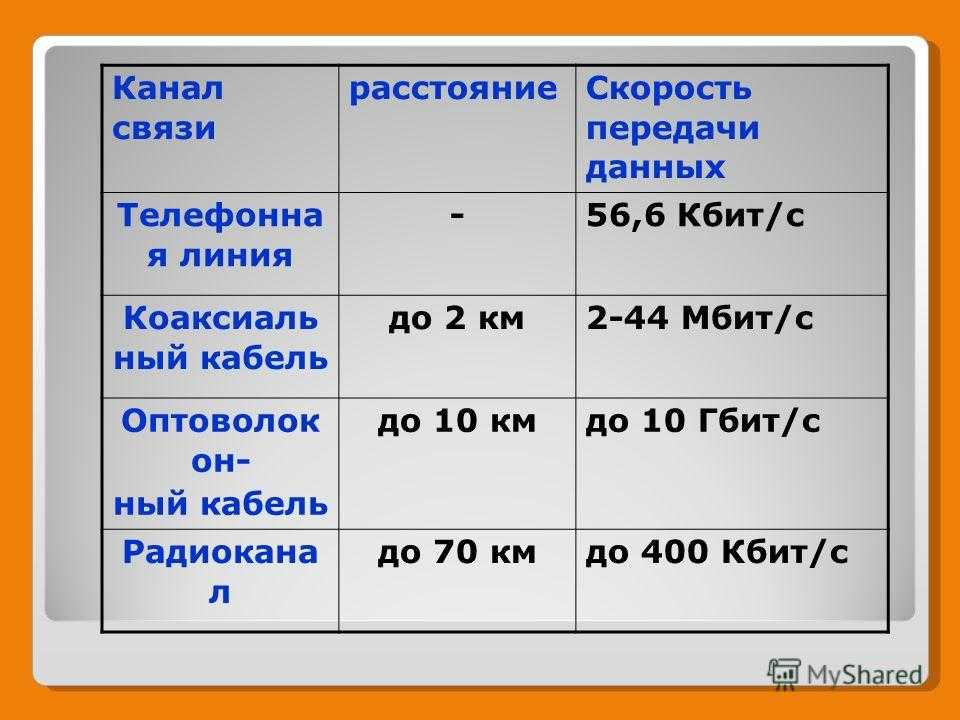
Скорость передачи информации на разных языках примерно одинакова
6 сент. 2019 г.

‹›×
На любом языке, независимо от скорости речи, в разговоре человек выдает 39 бит информации в секунду. Эксперты определили, что это примерно в два раза быстрее, чем код Морзе. Результаты исследования лингвистов былиопубликованы в Science Advances.
На любом языке, независимо от скорости речи, в разговоре человек выдает 39 бит информации в секунду. Эксперты определили, что это примерно в два раза быстрее, чем код Морзе. Результаты исследования лингвистов были опубликованы в Science Advances.
Согласно исследованиям, итальянцы — одна из самых быстро говорящих наций в мире. Они могут выдавать до девяти слогов в секунду. Немецкий язык — один из самых медленных. В среднем, немец может произнести пять- шесть слогов в секунду. Англичане выдают 6,19 слогов в секунду, испанцы — 7,82 , японцы — 7,84.
Исследования показали, что количество слогов за единицу времени зависит от информационной нагрузки этих слогов. К насыщенным смыслом слогам можно отнести, например, слово «рак». Будучи законченным словом, оно вызывает образ болезни или членистоногого. Предлог «на» имеет низкую плотность информации. Слог «пи», отделенный от слова, не имеет смысла вовсе.
Ученые начали исследования с письменных текстов на 17 языках и рассчитали плотность информации для каждого языка в битах. Результаты подсчетов показали, что, например, в японском языке, имеющем всего 643 слога, плотность информации составляет около пяти битов на слог. Английский с его 6949 слогами имеет плотность чуть более семи битов на слог. Вьетнамцы, со своей сложной системой из шести тонов (каждый из которых может дополнительно дифференцировать слог), возглавили чарт с показателем в восемь бит на слог.
Затем эксперименты проводили с десятью участниками, говорившими на 14 языках. Каждый из них читал вслух 15 одинаковых отрывков, которые были переведены на родной язык. Определяя, сколько времени людям потребовалось для чтения, исследователи вычислили среднюю скорость речи на язык, измеряемую в слогах в секунду, умножив эту скорость на скорость передачи в битах, исследователи рассчитали объем информации в секунду.
В итоге выяснилось, что каждый язык стремится к средней скорости 39,15 бит в секунду. Для сравнения, первый в мире компьютерный модем 1959 года имел скорость передачи 110 бит в секунду, а средняя скорость подключения к домашнему интернету сегодня составляет 100 миллионов бит в секунду.
исследование ученые
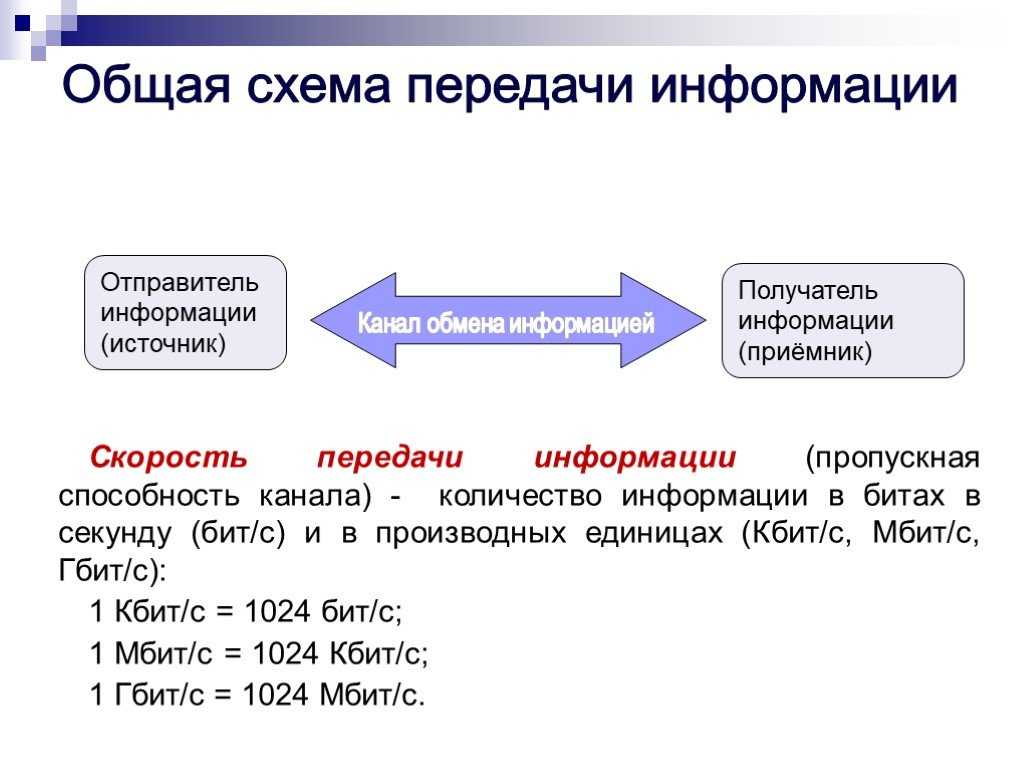
Время и память — основные характеристики алгоритмов
Алгоритмы описывают с помощью двух характеристик — времени и памяти.
Время — это… время, которое нужно алгоритму для обработки данных. Например, для маленького массива — 10 секунд, а для массива побольше — 100 секунд. Интуитивно понятно, что время выполнения алгоритма зависит от размера массива.
Но есть проблема: секунды, минуты и часы — это не очень показательные единицы измерения. Кроме того, время работы алгоритма зависит от железа, на котором он выполняется, и других внешних факторов. Поэтому время считают не в секундах и часах, а в количестве операций, которые алгоритм совершит. Это надёжная и, главное, независимая от железа метрика.
Когда говорят о Time Complexity или просто Time, то речь идёт именно о количестве операций. Для простоты расчётов разница в скорости между операциями обычно опускается. Поэтому, несмотря на то, что деление чисел с плавающей точкой требует от процессора больше действий, чем сложение целых чисел, обе операции в теории алгоритмов считаются равными по сложности.
Запомните: в О-нотации на операции с одной или двумя переменными вроде i++, a * b, a / 1024, max(a,b) уходит всего одна единица времени.
Память, или место, — это объём оперативной памяти, который потребуется алгоритму для работы. Одна переменная — это одна ячейка памяти, а массив с тысячей ячеек — тысяча ячеек памяти.
В теории алгоритмов все ячейки считаются равноценными. Например, int a на 4 байта и double b на 8 байт имеют один вес. Потребление памяти обычно называется Space Complexity или просто Space, редко — Memory.
Алгоритмы, которые используют исходный массив как рабочее пространство, называют in-place. Они потребляют мало памяти и создают одиночные переменные — без копий исходного массива и промежуточных структур данных. Алгоритмы, требующие дополнительной памяти, называют out-of-place. Прежде чем использовать алгоритм, надо понять, хватит ли на него памяти, и если нет — поискать менее прожорливые альтернативы.
Линейный поиск
Начнём с самого простого алгоритма — линейного поиска, он же linear search. Дальнейшее объяснение подразумевает, что вы знаете, что такое числа и как устроены массивы. Напомню, это всего лишь набор проиндексированных ячеек.
Допустим, у нас есть массив целых чисел arr, содержащий n элементов. Вообще, количество элементов, размер строк, массивов, списков и графов в алгоритмах всегда обозначают буквой n или N. Ещё дано целое число x. Для удобства обусловимся, что arr точно содержит x.
Задача: найти, на каком месте в массиве arr находится элемент 3, и вернуть его индекс.

Фото: Валерий Жила для Skillbox Media
Меткий человеческий глаз сразу видит, что искомый элемент содержится в ячейке с индексом 2, то есть в arr. А менее зоркий компьютер будет перебирать ячейки друг за другом: arr, arr… и так далее, пока не встретит тройку или конец массива, если тройки в нём нет.
Теперь разберём случаи:
Worst case. Больше всего шагов потребуется, если искомое число стоит в конце массива. В этом случае придётся перебрать все n ячеек, прочитать их содержимое и сравнить с искомым числом. Получается, worst case равен O(n). В нашем массиве худшему случаю соответствует x = 2.
Best case. Если бы искомое число стояло в самом начале массива, то мы бы получили ответ уже в первой ячейке. Best case линейного поиска — O(1). Именно так обозначается константное время в Big O Notation. В нашем массиве best case наблюдается при x = 7.
23 Вы устраиваетесь на работу, связанную с электронной торговлей. Круг ваших клиентов и задач очень разнообразен.
Выберите и соотнесите торговые площадки, которые подходят для решения разных задач по покупке и продаже товаров.
- Электронная площадка, на которой компании могут вести торговлю непосредственно с конечным покупателем
- Электронная площадка, на которой торговля осуществляется только между компаниями
- Электронная площадка, на которой представлены разные компании-продавцы, а покупатель может выбирать не только товар, но и условия покупки, формы оплаты, способы доставки и страхования товара
- Электронная площадка, которая позволяет проводить открытые и закрытые торги среди заинтересованных покупателей
Торговые площадки: Электронный аукцион, В2В-площадка, В2С-площадка, Маркетплейс
📑 Как рассчитать время чтения текста?
Поскольку обычно темп измеряется в словах за одну минуту, то для этого необходимо записать при помощи диктофона свою речь в течение 3-5-ти минут, потом высчитать получившиеся слова.
Далее, необходимо разделить все слова на количество минут.
Правило:
Сделать запись речи на камеру телефона. Подсчитать слова с помощью разных вариантов:
- Прослушать запись снова и просчитать на слух все слова;
- Загрузить запись в онлайн программу, с помощью которой речь переводится в текст.
После этого перевести записи в минуты. К примеру, если вы наговорили примерно на 4 минуты и 30 секунд, то тогда объем слов необходимо разделить на 4.5, поскольку 30 секунд — по сути полминуты.





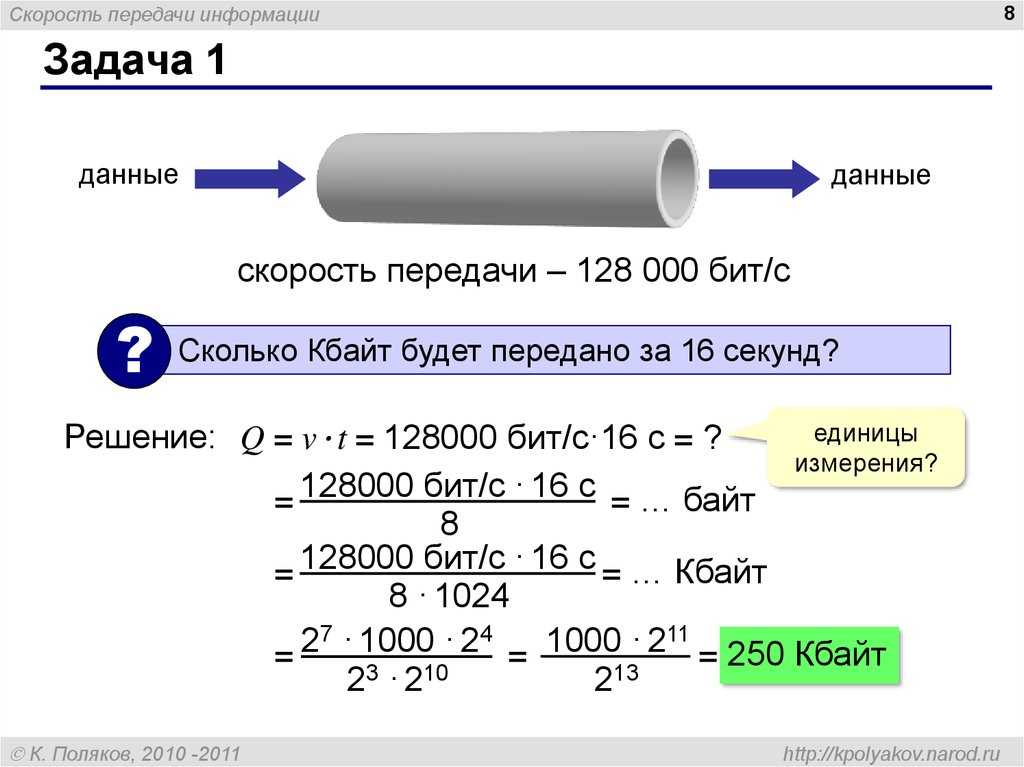
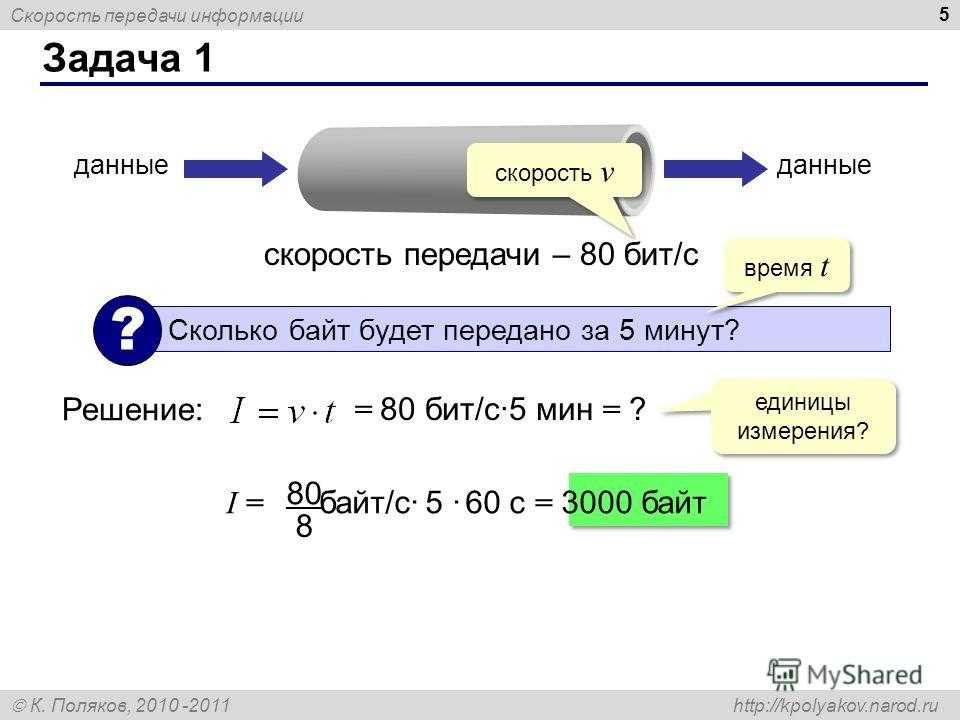


Как определить сложность алгоритма
Мы рассмотрели два алгоритма и увидели примеры их сложности. Но так и не поговорили о том, как эту сложность определять. Есть три основных способа.
Оценка «на глаз»
Первый и наиболее часто используемый способ. Именно так мы определяли сложность linear search и binary search. Обобщим эти примеры.
Первый случай. Есть алгоритм some_function, который выполняет действие А, а после него — действие В. На А и В нужно K и J операций соответственно.
В случае последовательного выполнения действий сложность алгоритма будет равна O(K + J), а значит, O(max (K, J)). Например, если А равно n^2, а В — n, то сложность алгоритма будет равна O(n^2 + n). Но мы уже знаем, что нас интересует только самая быстрорастущая часть. Значит, ответ будет O(n^2).
Второй случай. Посчитаем сложность действий или вызова методов в циклах. Размер массива равен n, а над каждым элементом будет выполнено действие А (n раз). А дальше всё зависит от «содержимого» A.
Посчитаем сложность бинарного поиска:
Если на каждом шаге A работает с одним элементом, то, независимо от количества операций, получим сложность O(n). Если же A обрабатывает arr целиком, то алгоритм совершит n операций n раз. Тогда получим O(n * n) = O(n^2). По такой же логике можно получить O(n * log n), O(n^3) и так далее.
Третий случай — комбо. Для закрепления соединим оба случая. Допустим, действие А требует log(n) операций, а действие В — n операций. На всякий случай напомню: в алгоритмах всегда идёт речь о двоичных логарифмах.
Добавим действие С с пятью операциями и вот что получим:
O(n * (n * log(n) + n) + 5) = O(n^2 * log(n) + n^2 + 5) = O(n^2 * log(n)).
Мы видим, что самая дорогая часть алгоритма — действие А, которое выполняется во вложенном цикле. Поэтому именно оно доминирует в функции.
Есть разновидность определения на глаз — амортизационный анализ. Это относительно редкий, но достойный упоминания гость. В двух словах его можно объяснить так: если на X «дешёвых» операций (например, с O(1)) приходится одна «дорогая» (например, с O(n)), то на большом количестве операций суммарная сложность получится неотличимой от O(1).
Частый пациент амортизационного анализа — динамический массив. Это массив, который при переполнении создаёт новый, больше оригинального в два раза. При этом элементы старого массива копируются в новый.
Практически всегда добавление элементов в такой массив «дёшево» — требует лишь одной операции. Но когда он заполняется, приходится тратить силы: создавать новый массив и копировать N старых элементов в новый. Но так как массив каждый раз увеличивается в два раза, переполнения случаются всё реже и реже, поэтому average case добавления элемента равен O(1).
Мастер-теорема
Слабое место прикидывания на глаз — рекурсия. С ней и правда приходится тяжко. Поэтому для оценки сложности рекурсивных алгоритмов широко используют мастер-теорему.
По сути, это набор правил по оценке сложности. Он учитывает, сколько новых ветвей рекурсии создаётся на каждом шаге и на сколько частей дробятся данные в каждом шаге рекурсии. Это если вкратце.
Метод Монте-Карло
Метод Монте-Карло применяют довольно редко — только если первые два применить невозможно. Особенно часто с его помощью описывают производительность систем, состоящих из множества алгоритмов.
Бинарный поиск
Следующая остановка — binary search, он же бинарный, или двоичный, поиск.
В чём отличие бинарного поиска от уже знакомого линейного? Чтобы его применить, массив arr должен быть отсортирован. В нашем случае — по возрастанию.
Часто binary search объясняют на примере с телефонным справочником. Возможно, многие читатели никогда не видели такую приблуду — это большая книга со списками телефонных номеров, отсортированных по фамилиям и именам жителей. Для простоты забудем об именах.
Итак, есть огромный справочник на тысячу страниц с десятками тысяч пар «фамилия — номер», отсортированных по фамилиям. Допустим, мы хотим найти номер человека по фамилии Жила. Как бы мы действовали в случае с линейным поиском? Открыли бы книгу и начали её перебирать, строчку за строчкой, страницу за страницей: Астафьев… Безье… Варнава… Ги… До товарища Жилы он дошёл бы за пару часов, а вот господин Янтарный заставил бы алгоритм попотеть ещё дольше.
Бинарный поиск мудрее и хитрее. Он открывает книгу ровно посередине и смотрит на фамилию, например Мельник — буква «М». Книга отсортирована по фамилиям, и алгоритм знает, что буква «Ж» идёт перед «М».
Алгоритм «разрывает» книгу пополам и выкидывает часть с буквами, которые идут после «М»: «Н», «О», «П»… «Я». Затем открывает оставшуюся половинку посередине — на этот раз на фамилии Ежов. Уже близко, но Ежов не Жила, а ещё буква «Ж» идёт после буквы «Е». Разрываем книгу пополам, а левую половину с буквами от «А» до «Е» выбрасываем. Алгоритм продолжает рвать книгу пополам до тех пор, пока не останется единственная измятая страничка с заветной фамилией и номером.
Перенесём этот принцип на массивы. У нас есть отсортированный массив arr и число 7, которое нужно найти. Почему поиск называется бинарным? Дело в том, что алгоритм на каждом шаге уменьшает проблему в два раза. Он буквально отрезает на каждом шаге половину arr, в которой гарантированно нет искомого числа.

Фото: Валерий Жила для Skillbox Media
На каждом шаге мы проверяем только середину. При этом есть три варианта развития событий:
- попадаем в 7 — тогда проблема решена;
- нашли число меньше 7 — отрезаем левую половину и ищем в правой половине;
- нашли число больше 7 — отрезаем правую половину и ищем в левой половине.
Почему это работает? Вспомните про требование к отсортированности массива, и всё встанет на свои места.
Итак, смотрим в середину. Карандаш будет служить нам указателем.

Фото: Валерий Жила для Skillbox Media
В середине находится число 5, оно меньше 7. Значит, отрезаем левую половину и проверенное число. Смотрим в середину оставшегося массива:

Фото: Валерий Жила для Skillbox Media
В середине число 8, оно больше 7. Значит, отрезаем правую половинку и проверенное число. Остаётся число 7 — как раз его мы и искали. Поздравляю!

Фото: Валерий Жила для Skillbox Media
Теперь давайте попробуем записать это в виде красивого псевдокода. Как обычно, назовём середину mid и будем перемещать «окно наблюдения», ограниченное двумя индексами — low (левая граница) и high (правая граница).
Алгоритм организован рекурсивно, то есть вызывает сам себя на строках 7 и 9. Есть итеративный вариант с циклом, без рекурсии, но он кажется мне уродливым. Если не находим искомый элемент, возвращаем -1. В начале работы алгоритма значение low совпадает с началом массива, а high — с его концом. И они бегут навстречу друг другу…
Чтобы запускать алгоритм, не задумываясь о начальных значениях индексов low и high, можно написать такую функцию-обёртку:
Посчитаем сложность бинарного поиска:
Best case. Как и у линейного поиска, лучший случай равен O(1), ведь искомое число может находиться в середине массива, и тогда мы найдём его с первой попытки.

![Скорость устной речи [1978 кондратов а.м. - звуки и знаки]](https://sttk38.ru/wp-content/uploads/8/0/9/80963ca44f546e5c7a85493941bfd994.jpeg)







Worst case. Чтобы найти худший случай, нужно ответить на вопрос: «Сколько раз нужно разделить массив на 2, чтобы в нём остался один элемент?» Или найти минимальное число k, при котором справедливо 2^k ≥ n.
Надеюсь, что большинство читателей смогут вычислить k. Но на всякий случай подскажу решение: k = log n по основанию 2 (в алгоритмах практически все логарифмы двоичные). Поэтому worst case бинарного поиска — O(log n).
Программа определение хронометража — времени произнесения текста
Хрономер текста — это специальный онлайн инструмент, предназначенный для автоматического подсчёта рекомендуемого количества определённого текста в ролик.
Он способен переводить слова как в минуты, так и в секунды. Также при этом есть возможность узнать тайминг текста.
Для определения хронометража, следует внести в программу только тот текст, который будет озвучен (например, рекламный). При этом другие пояснения и разные комментарии необходимо убрать. По итогу, на выходе можно будет получить примерный хронометраж текста, выраженный в секундах.
Чтобы рассчитать сколько времени займёт текст, такая программа учтёт произношение как различных цифр, так и наличие знаков. Также сюда можно отнести и особенности озвучки в классическом варианте.
Вы можете самостоятельно обрабатывать собственный сценарий непосредственно в самом окне программы до того момента, пока вам не удастся получить то, что нужно. Также необходимо выбрать скорость для начитки вашего проекта.
40 Вам в почту пришло письмо от gosuslugi о том, что произошла ошибка: ваш работодатель неправильно подал данные и вы заплатили больше налогов, чем нужно.
Разницу можно вернуть, сумма к возврату – от 12 438 рублей за 2020 год (с учетом антиковидных стимулирующих выплат). Для точного расчета и получения выплаты необходимо указать свои данные: ФИО, дату рождения и платежные реквизиты для перевода вам средств. Ваши действия?
- Я воспользуюсь предложением, так как уверен, что мне точно задолжали
- Я знаю, что это могут быть мошенники, но без подтверждения по СМС они не смогут списать средства с моей карты, поэтому буду аккуратен, но попробую получить выплату
- Я запишу информацию и обращусь к своему работодателю за разъяснениями
- Я знаю, что ковидные надбавки многим обещали, надо проверить, сколько мне полагается, и получить их. Я доверяю письмам от Gosuslugi
Скорость устной речи
Поскольку основное средство общения — разговорная речь, то, вероятно, важно знать не только число бит, приходящихся на тот или иной звук, но и скорость передачи информации при разговоре. И в нашей стране, и за рубежом было проведено множество исследований, посвященных этой теме
Кодовой единицей для письменного текста является буква. Для устной речи — фонема, своеобразный атом звукового языка (о нем рассказывает очерк «Формулы фонемы»). Опыты по угадыванию фонем, подсчеты частоты их употребления, наконец, анализ спектрограмм фонем и сравнение их с изображениями букв в машинописном тексте — все это позволило определить величину избыточности звукового кода языка. Она оказалась примерно такой же, как и величина избыточности алфавитного кода. Только в зависимости от «подъязыка», от стиля и характера разговора эта избыточность может варьировать в еще больших пределах, чем «запас прочности» письменного текста
И в нашей стране, и за рубежом было проведено множество исследований, посвященных этой теме. Кодовой единицей для письменного текста является буква. Для устной речи — фонема, своеобразный атом звукового языка (о нем рассказывает очерк «Формулы фонемы»). Опыты по угадыванию фонем, подсчеты частоты их употребления, наконец, анализ спектрограмм фонем и сравнение их с изображениями букв в машинописном тексте — все это позволило определить величину избыточности звукового кода языка. Она оказалась примерно такой же, как и величина избыточности алфавитного кода. Только в зависимости от «подъязыка», от стиля и характера разговора эта избыточность может варьировать в еще больших пределах, чем «запас прочности» письменного текста.
Возьмем разговор двух друзей, понимающих, как говорится, друг друга с полуслова. В их речи будут умолчания, намеки, пропуски слов и «съедания» отдельных звуков и даже грамматических окончаний (в письменной речи это недопустимо). Вполне понятно, что избыточность такого разговора будет, пожалуй, еще меньше, чем избыточность телеграфного стиля, о котором мы рассказывали.
А вот другой разговор: диалог между дежурным на аэродроме и пилотом, находящимся в воздухе. Во-первых, этот разговор по радио имеет определенные стандарты. Во-вторых, тематика его ограничена. В-третьих, он происходит в условиях шума, который создает самолет, поэтому приходится повторять нерасслышанные или нечетко услышанные слова и фразы. В-четвертых — и это самое главное,- ошибка в одно слово может стоить жизни пилоту. В итоге избыточность такого разговора равна девяноста шести процентам. Иными словами, из ста слов пилот и диспетчер предпочитают говорить девяносто шесть «лишних», зато это гарантирует им надежность связи и, стало быть, безопасность жизни пилота, ведущего самолет.
Скорость передачи информации при таком разговоре очень невелика. Она равна примерно двум десятым бита в секунду. Обычная скорость передачи информации при разговоре примерно в двадцать — тридцать раз больше, она равна пяти — шести битам. Но это при нормальном темпе речи. Как известно, этот темп можно значительно увеличить: очень медленная речь почти в пять раз медленней, чем очень быстрая. Сколько же информации за секунду может передать человек при очень быстром разговоре?
Вот любопытный расчет. Человеческое ухо может воспринять, а человеческий рот произнести чудовищно много различных звуков. Пропускная способность человеческого уха, то есть количество информации, которое может быть передано в единицу времени, равна пятидесяти тысячам бит в секунду (по телефону мы можем передать только тридцать тысяч бит в секунду, он сужает диапазон). Величина эта огромна. Но, конечно, мозг получает не всю звуковую информацию, он ее фильтрует, просеивает сквозь сито фонем.
Сколько же информации доходит до мозга? Насколько частым является это сито? Оказывается, оно очень частое. Настолько частое, что количество информации уменьшается в тысячу раз: уже не пятьдесят тысяч, а просто пятьдесят бит в секунду получает мозг, воспринимая предельно быструю речь.
Но и это величина немалая. Опыты показывают, что большее количество информации наш мозг и не в силах обработать сознательно (например, опытная машинистка или пианист передают сигналы со скоростью двадцать пять бит в секунду). Таким образом, скорость передачи информации при предельно быстром разговоре (сорок — пятьдесят бит в секунду) в двести — триста раз превышает скорость передачи информации при разговоре диспетчера с летчиком и в десять раз скорость разговора в нормальном темпе.